Abstract

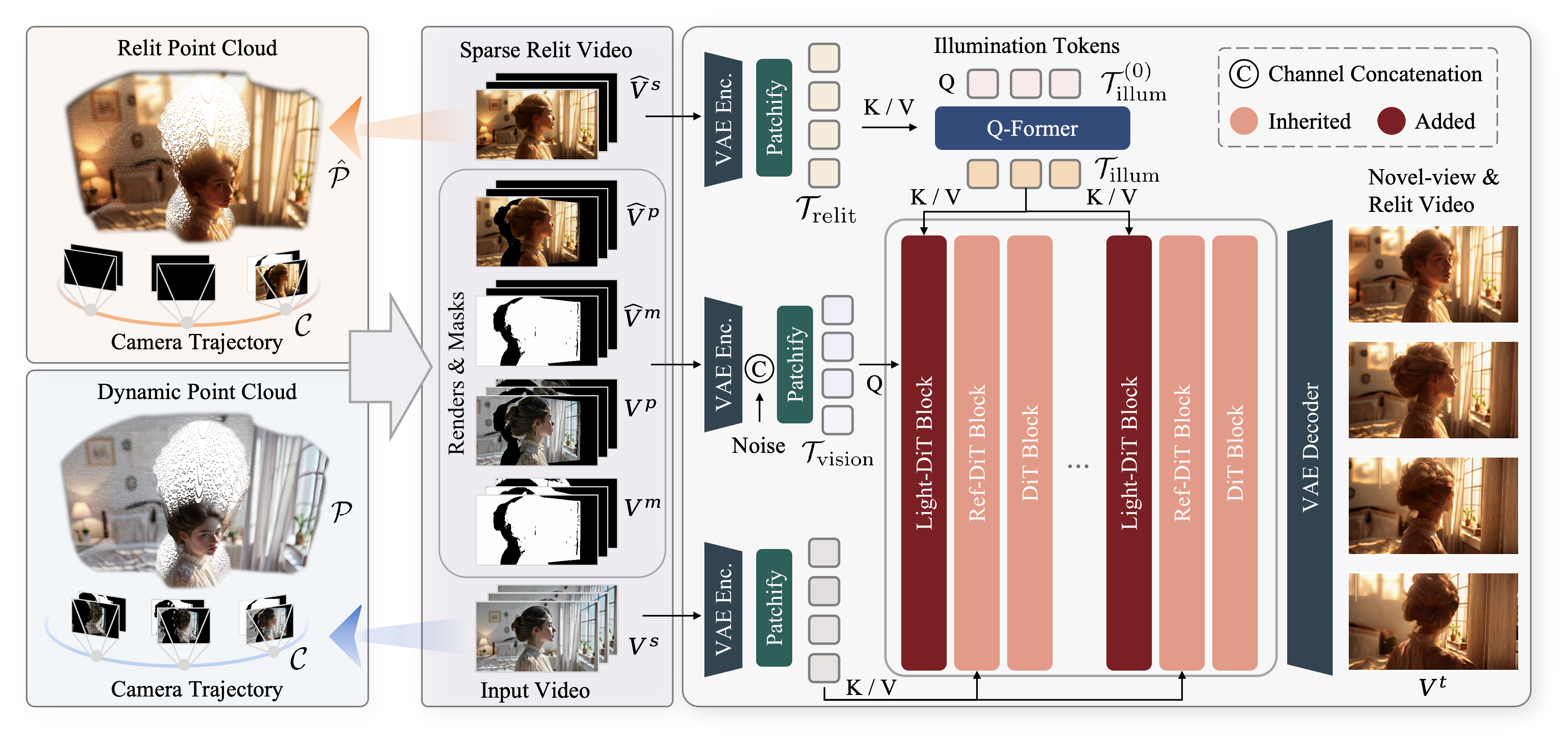
Recent advances in illumination control extend image-based methods to video, yet still facing a trade-off between lighting fidelity and temporal consistency. Moving beyond relighting, a key step toward generative modeling of real-world scenes is the joint control of camera trajectory and illumination, since visual dynamics are inherently shaped by both geometry and lighting. To this end, we present Light-X, a video generation framework that enables controllable rendering from monocular videos with both viewpoint and illumination control. 1) We propose a disentangled design that decouples geometry and lighting signals: geometry and motion are captured via dynamic point clouds projected along user-defined camera trajectories, while illumination cues are provided by a relit frame consistently projected into the same geometry. These explicit, fine-grained cues enable effective disentanglement and guide high-quality illumination. 2) To address the lack of paired multi-view and multi-illumination videos, we introduce Light-Syn, a degradation-based pipeline with inverse-mapping that synthesizes training pairs from in-the-wild monocular footage. This strategy yields a dataset covering static, dynamic, and AI-generated scenes, ensuring robust training. Extensive experiments show that Light-X outperforms baseline methods in joint camera-illumination control. Besides, our model surpasses prior video relighting methods in text- and background-conditioned settings. Ablation studies further validate the effectiveness of the disentangled formulation and degradation pipeline.